Normality Test: Kolmogorov–Smirnov (KS) Test with one-sample test example
Normality is a very important assumption for many statistical inference. There are several statistics tests that are useful for testing normality. For example:
1. Shapiro-Wilk (SW) test
2. Kolmogorov-Smirnov (KS) test
3. Anderson-Darling (AD) test
Today, we are going to introduce Kolmogorov-Smirnov Test (known as K-S Test), which is one of the most popular statistics tests for normality.

In this article, we will go through the following about Kolmogorov-Smirnov Test with an example.
1. Objective of K-S Test
2. Assumption
3. Null Hypothesis of K-S Test
4. How does K-S Test work?
5. K-S Test Statistics
6. Characteristics of K-S Test
Objective of K-S Test
K-S test can be used for one-sample testing / two-sample testing.
One-sample testing means that we are comparing the empirical cumulative distribution from the sample with the hypothesized distribution (e.g. Normal Distribution / Poisson Distribution). If we fail to reject the null hypothesis, then we can conclude the sample follows the hypothesized distribution.
Two-sample testing means that we are comparing the empirical cumulative distribution from two different samples of data. If we fail to reject the null hypothesis, then we can conclude these two samples follow the same distribution. However, we do not know what distribution they follow.
Assumptions
- [For both testing] Data are independent and identically distributed (i.i.d) in each sample.
- [In Two-sample testing] The two samples are mutually independent.
Null Hypothesis of K-S Test
- [In One-sample testing] The sample follows the hypothesized distribution.
- [In Two-sample testing] The two samples follows the same distribution.
How does K-S Test work?
What K-S Test does is to calculate the maximum distance between two distributions:
- [In One-sample testing] the empirical cumulative distribution function of the sample and the cumulative distribution function of the hypothesized distribution
- [In Two-sample testing] the empirical cumulative distribution functions of two samples
If both distributions are the same or similar, the maximum distance should be small enough. In the graph below, red line is the hypothesized cumulative distribution and the blue line is the empirical cumulative distribution.

Noted that we are using the cumulative distribution function for comparison. Therefore we need to re-arrange the data order (i.e. ascending) so that the sample data is independent and identically distributed (i.i.d.) and ordered.
The following is a one-sample testing example:
Sample Data From Gamma(2,4):
7,10,1,8,5,9,8,5,4,2,7,9,1,0,2,10,12,19,6,12
After re-order:
0,1,1,2,2,4,5,5,6,7,7,8,8,9,9,10,10,12,12,19
The empirical cumulative distribution function of sampled data is given:
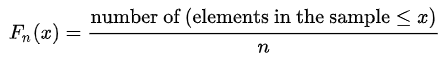
Sample Data:
0,1,1,2,2,4,5,5,6,7,7,8,8,9,9,10,10,12,12,19
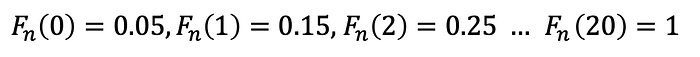
After calculating the empirical cumulative distribution, you can calculate the hypothesized cumulative distribution. In our example, the hypothesized distribution is gamma cumulative distribution function:
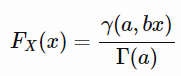
where:
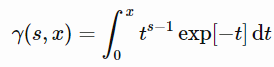
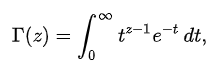
From the gamma cumulative distribution function, we have
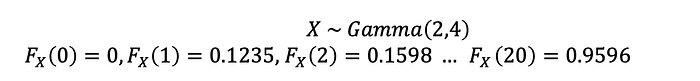
K-S Test Statistics
[In One-sample testing] The Kolmogorov–Smirnov statistic for a given cumulative distribution function is

[In Two-sample testing] The Kolmogorov–Smirnov statistic for a given cumulative distribution function is

In our example,
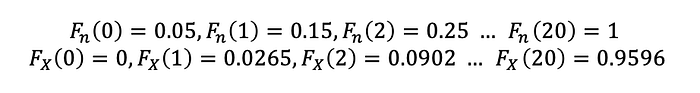
As a result,
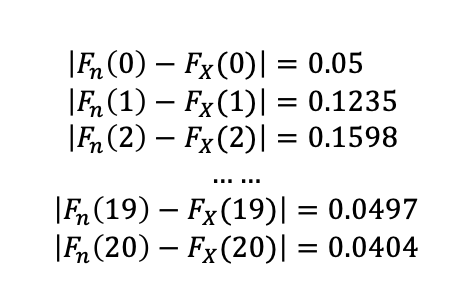
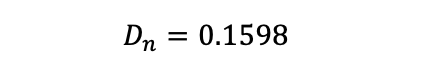
With number of sample = 20 and significant level (α) of 0.05, the critical value obtained from the K-S table below is 0.29407.
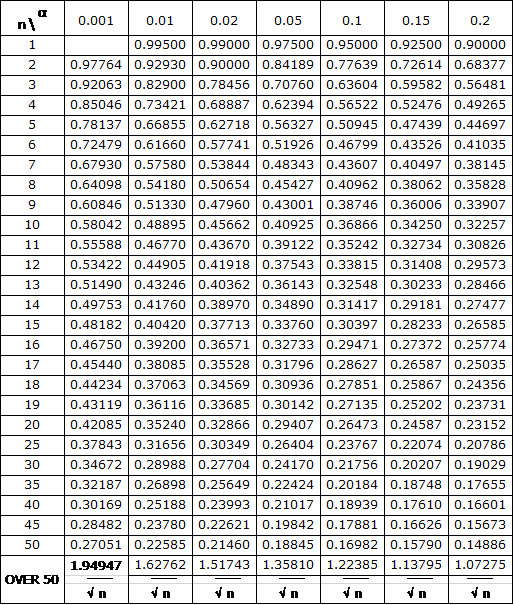
As the critical value is larger than our K-S test statistics, we fail to reject the null hypothesis that the sample data follow gamma distribution.
Characteristics of K-S Test
- Serve as a goodness of fit test
- Does not report any confidence interval
Advantage:
- Distribution-free (no population distribution to be known)
- Applicable on data with any sample size
- K-S Test statistics is easy to calculate
Disadvantage:
- Parameters of the distribution has to be known (For one-sample testing)
- Not applicable on discrete distribution
If you like this article, give me a clap and share it to your friends. You may also leave me a comment / message too.
And don’t forget to follow me for pre Python / AI / Statistics content.
